[PART 1]. 基本Anaconda概論¶

另外提供一些快捷鍵的方法¶

[PART 2]. 開始使用 pandas¶
- Pandas簡單來說就是把Excel的表格觀念丟到Python,在Excel所有的操作都可以透過Pandas的函式做簡單的處理,想是欄位的加總、分群、樞紐分析表、小計、畫折線圖、圓餅圖等等…
- Pandas背後的數值型態都是Numpy,Numpy的資料結構可以幫助Pandas在執行運算上更有效率以及更省記憶體。
- matplotlib.pyplot 是視覺化套件

[2.2 標準開始動作]. 如果你用python的目標是科學計算或數值分析,基本是引⼊三個套件¶
In [3]:
%matplotlib inline
##將後續畫圖的結果直接顯現在網頁中
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd #
[2.3]. 輸入資料與資料格式¶
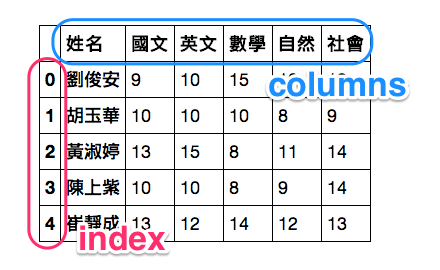
用 df 是標準的叫法 (雖然這名稱我們隨便取也可以), 意思是 Data Frame, 這是 pandas 兩大資料結構之一。我們可以把 Data Frame 想成一張表格 (雖然其實可以是很多張表格)。
我們來看看我們 df 的前五筆資料。
In [4]:
df = pd.read_csv("grades.csv") #這裡的df是 data-frame的意思,你也可以用其他名稱代替
df.head() #看前五筆資料
Out[4]:
In [5]:
df.tail() #看後面幾筆
Out[5]:
怎麼查語法¶
- 假設我不知道上面這行 df.tail() 在幹嘛的
In [6]:
#??tail()
Excel 檔也可以快速讀入¶
不只 CSV 檔, 很多資料檔案, 像 Excel 檔都很容易在 pandas 完成。使用法是這樣:
df2 = pd.read_excel('filename.xls', 'sheetname')
其中 sheetname 那裡要放工作表的名稱, 如果是中文的最好改成英文。
In [7]:
df["數學"] #列出某一行
Out[7]:
[PART 3]. 基本敘述性統計¶
In [8]:
df.數學.mean()
Out[8]:
In [9]:
df.國文.mean()
Out[9]:
In [10]:
df.數學.std()
Out[10]:
In [11]:
df.describe() #基本統計量
Out[11]:
In [12]:
df[["國文", "英文", "數學"]].sum(1)#選三科相加
Out[12]: