[標準開始動作]. 如果你用python的目標是科學計算或數值分析,基本是引⼊三個套件¶
In [1]:
%matplotlib inline
##將後續畫圖的結果直接顯現在網頁中
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd #
[PART 1]. 輸入資料與資料格式¶
用 df 是標準的叫法 (雖然這名稱我們隨便取也可以), 意思是 Data Frame, 這是 pandas 兩大資料結構之一。我們可以把 Data Frame 想成一張表格 (雖然其實可以是很多張表格)。
我們來看看我們 df 的前五筆資料。
In [2]:
df = pd.read_csv("grades.csv") #這裡的df是 data-frame的意思,你也可以用其他名稱代替
df.head() #看前五筆資料
Out[2]:
In [3]:
df.describe() #基本統計量
Out[3]:
In [4]:
df.corr() #相關係數
Out[4]:
In [5]:
df[["國文", "英文", "數學"]].sum(1)#選三科相加
Out[5]:
In [6]:
df[df.數學==15] #找出數學滿級分的同學
Out[6]:
In [7]:
df[(df.數學==15) & (df.英文==15)] #找出數學和英文都滿級分的同學。要注意 and 要用 &, or 要用 |。每個條件一定要加弧號
Out[7]:
In [8]:
df[(df.數學==15) | (df.英文==15)] #找出數學 或 英文 滿級分的同學。要注意 and 要用 &, or 要用 |。每個條件一定要加弧號
Out[8]:
In [9]:
df["國英數"] = df[["國文", "英文", "數學"]].sum(1) #新增一個欄位
df.head()
Out[9]:
In [10]:
df["加權"] = df.數學*2 + df.英文
df.head()
Out[10]:
In [11]:
df["總級分"] = df[["國文", "英文", "數學", "社會", "自然"]].sum(1)
df.head()
Out[11]:
2.2 排序¶
In [12]:
df.sort_values(by=["總級分"], ascending=False).head(20) #由大排到小
Out[12]:
In [13]:
df.sort_values(by=["加權", "總級分"], ascending=False).head(20) #先比"加權"再比"總級分"
Out[13]:
2.3 刪除某一欄或列¶
In [14]:
df.drop("總級分", axis=1).head(10) #刪掉總級分的那行。
Out[14]:
In [15]:
df.drop(5).head(10) #刪掉列就是指定要刪去的 index。
Out[15]:
In [16]:
df.drop(df[df.姓名=="李士賢"].index).head(10) #或是你也可以這樣寫
Out[16]:
In [17]:
#同理可證,我如果只想看特定學生的分數呢
df[df.姓名=="林金鳳"]
Out[17]:
[PART 3]. 基本Data ETL Ⅱ¶
在本小節,我們要討論的是資料合併 (Pandas Merging)。但是在Pandas中,有關資料合併共有三個函數: Concat 函數、Merge 函數和 Join 函數
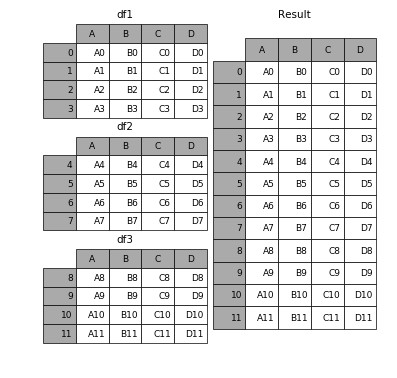
Concat 函數可以在下方或旁邊合併一個或多個 dataframe(取決於如何定義軸)¶
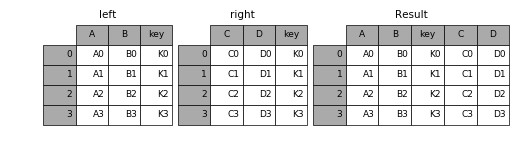
Merge 函數在作爲主鍵的指定公共列上合併多個 dataframe¶
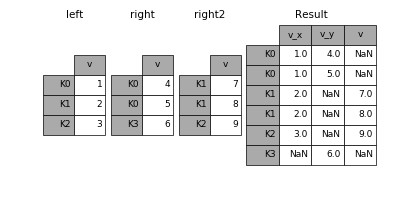
Join 函數合併兩個 dataframe 的方法與 merge 函數類似。但是,它根據索引合併 dataframe,而不是某些指定列。¶
在本小節,我們僅介紹Merge函數¶
In [18]:
#老規矩,起手式
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
In [19]:
#載入資料
user_usage = pd.read_csv("user_usage.csv") # 240位手機使用者的使用習慣
user_device = pd.read_csv("user_device.csv")# 272位使用者的手機品牌與系統
devices = pd.read_csv("android_devices.csv")# 14546筆Android整體手機的品牌
print("user_usage dimensions: {}".format(user_usage.shape))
print("user_device dimensions: {}".format(user_device.shape))
print("devices dimensions: {}".format(devices.shape))
In [20]:
user_usage.head() #手機使用者的使用習慣
Out[20]:
In [21]:
user_device.head()
Out[21]:
In [22]:
devices.head(10)
Out[22]:
[3.1] 第一次Merge¶
merge的參數
on:列名,join用來對齊的那一列的名字,用到這個參數的時候一定要保證左表和右表用來對齊的那一列都有相同的列名。
left_on:左表對齊的列,可以是列名,也可以是和dataframe同樣長度的arrays。
right_on:右表對齊的列,可以是列名,也可以是和dataframe同樣長度的arrays。
left_index/ right_index: 如果是True的haunted以index作為對齊的key
how:數據融合的方法。
sort:根據dataframe合併的keys按字典順序排序,默認是,如果置false可以提高表現。
[merge的默認合併方法]:¶
- merge用於表內部基於 index-on-index 和 index-on-column(s) 的合併,但默認是基於index來合併。
- pandas 套件的 merge() 方法預設是inner join,如果我們希望使用不同的合併方式,我們可以在 how =參數指定為 left、right 或 outer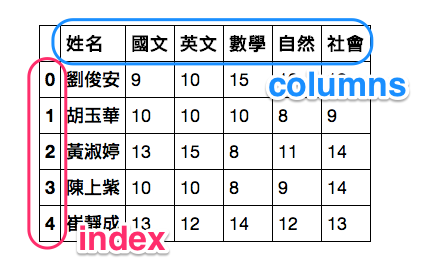
將 user_usage 及 user_device 兩個表格合併¶
In [23]:
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id')
result.head(10)
Out[23]:
In [24]:
#我們來看看合併之後,剩下多少 dimensions
print("result dimensions: {}".format(result.shape))
In [25]:
#成功合併及失敗合併各多少筆
user_usage['use_id'].isin(user_device['use_id']).value_counts()
Out[25]:
[3.2] Left merge¶
- 使用左邊data frame的key當作合併的依據
- pd.merge(left,right,how='left',on=['key1','key2'])
In [28]:
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id', how='left')
In [29]:
print("user_usage dimensions: {}".format(user_usage.shape))
print("result dimensions: {}".format(result.shape))
print("There are {} missing values in the result.".format(
result['device'].isnull().sum()))
In [30]:
result.head(10)
Out[30]:
[3.3] Right merge¶
- 使用右邊data frame的key當作合併的依據
- pd.merge(left,right,how='right',on=['key1','key2'])
In [31]:
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id', how='right')
In [32]:
print("user_device dimensions: {}".format(user_device.shape))
print("result dimensions: {}".format(result.shape))
print("There are {} missing values in the 'monthly_mb' column in the result.".format(
result['monthly_mb'].isnull().sum()))
print("There are {} missing values in the 'platform' column in the result.".format(
result['platform'].isnull().sum()))
In [33]:
result.head()
Out[33]:
[3.3] Outer merge¶
- 使用相同的key當作合併的依據
- pd.merge(left,right,how='outer',on=['key1','key2'])
In [34]:
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id', how='outer', indicator=True)
In [35]:
print("Outer merge result has {} rows.".format(result.shape))
print("There are {} rows with no missing values.".format(
(result.apply(lambda x: x.isnull().sum(), axis=1) == 0).sum()))
In [36]:
result.iloc[[0, 1, 200,201, 350,351]]
Out[36]:
[3.4] Final Merge : adding device manufacturer¶
In [37]:
# First, add the platform and device to the user usage.
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id',
how='left')
In [38]:
# Now, based on the "device" column in result, match the "Model" column in devices.
devices.rename(columns={"Retail Branding": "manufacturer"}, inplace=True)
result = pd.merge(result,
devices[['manufacturer', 'Model']],
left_on='device',
right_on='Model',
how='left')
In [39]:
result.head()
Out[39]:
Calculating statistics on final result¶
In [40]:
result.groupby("manufacturer").agg({
"outgoing_mins_per_month": "mean",
"outgoing_sms_per_month": "mean",
"monthly_mb": "mean",
"use_id": "count"
})
Out[40]:
In [ ]: