- #### seaborn是一個建立在matplot之上,可用於製作豐富和非常具有吸引力統計圖形的Python庫。
- #### Seaborn旨在將可視化作爲探索和理解數據的核心部分,有助於幫人們更近距離了解所研究的數據集。

字形編碼問題¶
- 在matplotlib 或 Seaborn 中,對於中文必須特別設定,否則圖不會顯示中文
- 請採用以下設定,請參考
- 建議:
- Mac可用字體:SimHei
- Windows 可用字體:Microsoft JhengHei
STEP1: 先用以下程式碼找到目前字體路徑,確認目前是抓哪個字體¶
In [1]:
from matplotlib.font_manager import findfont, FontProperties
findfont(FontProperties(family=FontProperties().get_family()))
Out[1]:
STEP2:使用以下程式碼去尋找設定檔路徑¶
In [2]:
import matplotlib
matplotlib.matplotlib_fname()
Out[2]:
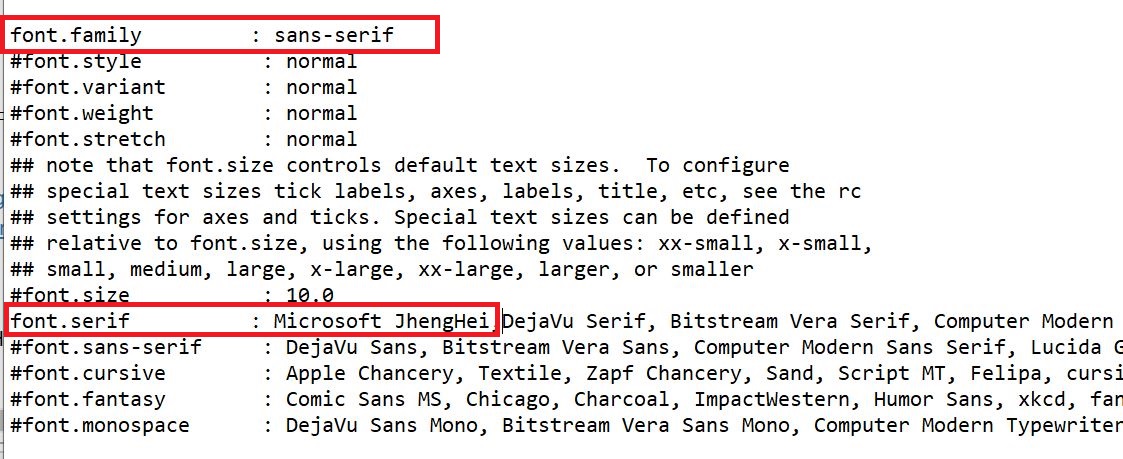
- 1.找出 C:\Users\user\Anaconda3\lib\site-packages\matplotlib\mpl-data\matplotlibrc 檔案,然後用記事本打開
- 2.將font.family與font.serif註解(#)移除,並在font.serif後方加入Microsoft JhengHei
STEP3: 刪除.matplotlib快取資料夾¶
- 然後刪除.matplotlib 資料夾,因為.matplotlib 資料夾裡面有舊有的matplotlib 快取(cache)檔案,為避免更新後的字體在讀取到舊的快取,所有要刪除。

STEP4:放入字體至matplotlib指定字體路徑¶
- 將msj文字檔(載點,為其他網友提供)下載,以msj命名之,在儲存到以下路徑資料夾 : C:\Users\您的使用者名稱\Anaconda3\Lib\site-packages\matplotlib\mpl-data\fonts\ttf

STEP5: 使用rcParams 參數指定字體¶
In [7]:
#測試一下
%matplotlib inline
##將後續畫圖的結果直接顯現在網頁中
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns #加入seaborn套件
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei']
plt.rcParams['axes.unicode_minus'] = False
plt.plot((1,2,3),(4,3,-1))
plt.title("聲量圖")
plt.ylabel("文章數量")
plt.xlabel("品牌名稱")
plt.show()

[標準開始動作]. 如果你用python的目標是科學計算或數值分析,基本是引⼊三個套件¶
In [5]:
%matplotlib inline
##將後續畫圖的結果直接顯現在網頁中
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns #加入seaborn套件
[Part 1]. 基本敘述性統計¶
tips(小費)數據集。小費數據集,是一個餐廳侍者收集的關於小費的數據,其中包含了七個變量,包括
- total_bill: 總費用
- tip: 付小費的金額
- sex: 付款者性別
- smoker: 是否吸菸
- day: 日期
- time: 給小費的時段
- size: 顧客人數。
[主要分析目的]. 通過數據分析和建模,可幫助餐廳侍者預測來餐廳就餐的顧客是否會會支付小費。¶
In [9]:
tips = pd.read_csv('tips.csv')
In [10]:
tips.head() #看前五筆資料
Out[10]:
In [11]:
tips.tail() #看後面幾筆
Out[11]:
In [12]:
tips.describe() #基本統計量,只會列出屬"量"資料
Out[12]:
[Part 2]. Visualization to EDA¶
- Seaborn 套件是以 matplotlib 為基礎建構的高階繪圖套件,讓使用者更加輕鬆地建立圖表,我們可以將它視為是 matplotlib 的補強
In [13]:
sns.set(style="ticks")
In [14]:
sns.scatterplot(x="total_bill", y="tip",
hue="time",
data=tips)
Out[14]:

2-1.次數分配圖¶
In [15]:
sns.distplot(tips['total_bill'])
Out[15]:

In [16]:
sns.distplot(tips['total_bill'],kde = False) # kde = Kernel Density
Out[16]:

上圖顯示,顧客在餐廳的消費總金額主要是在5-35的範圍內分佈的(右偏分佈)¶
2-2.count plot¶
In [17]:
sns.countplot(x = 'smoker', data = tips)
Out[17]:

來餐廳就餐的顧客,不抽菸者比會抽菸者多¶
In [18]:
sns.barplot(x="day", y="total_bill", data=tips)
Out[18]:

In [19]:
sns.countplot(x = 'time', data = tips)
Out[19]:

顧客來餐廳就餐,主要是來晚飯多一些,來吃午餐的總次數更少一些¶
In [20]:
sns.countplot(x = 'size', data = tips)
Out[20]:

個人來餐廳就餐的總次數高於其他人次¶
In [21]:
sns.countplot(x = 'day', data = tips)
Out[21]:

消費次數來說,週六最高¶
2-3. Bar-plot¶
In [22]:
sns.barplot(x="day", y="total_bill", data=tips)
Out[22]:

但顧客主要是週日、週六、週四來餐廳就餐,但消費金額是周日最高¶
In [24]:
sns.barplot(x="day", y="total_bill", hue="sex", data=tips)
Out[24]:

就餐時消費的賬單,這家餐廳男性的消費較多(男性買單的次數會比由女性買單的次數多一些)¶
In [25]:
sns.barplot(x="time", y="tip", data=tips,
order=["Dinner", "Lunch"])
Out[25]:

In [26]:
from numpy import median
sns.barplot(x="day", y="tip", data=tips, estimator=median) #用每天的中位數去估計小費的高低
Out[26]:

[Part 3].較進階的語法¶
kind : { “scatter” | “reg” | “resid” | “kde” | “hex” }, optional
Kind of plot to draw.
3-1. Joint-Plot¶
In [23]:
sns.jointplot(x = 'total_bill', y = 'tip', data = tips)
Out[23]:

- ### 顧客主要消費在10-30元之間,
- ### 對應給侍者小費的錢在1-5元之間
In [24]:
sns.jointplot(x = 'total_bill', y = 'tip', data = tips,kind = 'hex' ) # 清晰地視覺化視圖,顏色的深度代表頻率
Out[24]:

- ### 消費總金額集中在10-20元之間,小費集中在1-3.5元之間
- ### 但這並不能證明"消費金額越高,小費就給的越多"
In [25]:
sns.jointplot(x = 'total_bill', y = 'tip', data = tips ,kind = 'kde')
Out[25]:

In [26]:
sns.jointplot(x = 'total_bill', y = 'tip', data = tips ,kind = 'reg')
Out[26]:

做一條簡單的迴歸線,它表明了小費的金額是隨着總賬單金額的增加而增加的¶
3-2.Pair-plot¶
我們可看不同變數之間的散佈圖狀況¶
In [27]:
sns.pairplot(tips)
Out[27]:

數據集中在"消費總額、小費金額以及顧客數量"三個變量之間¶
In [28]:
sns.pairplot(tips ,hue ='sex', markers=["o", "s"]) #o是圓圈,s是方塊
#看看性別在不同變數間的關係
# hue ='sex' 以性別當圖標
Out[28]:

- ### 使用兩種不同的顏色用於區分性別
- ### 這間餐廳的男性顧客較多,但性別是否造成給小費高低的差別,目前無法辨識
3-3. Box-plot¶
In [29]:
sns.boxplot(x = 'day', y= 'total_bill', data = tips)
Out[29]:

大部分賬單是在週六和週日支付的¶
In [30]:
sns.boxplot(x = 'day', y= 'total_bill', data = tips, hue = 'sex') # hue = 'sex'以性別當圖標
Out[30]:

- ### 只有在週六時,女性買單的次數會比男性多。
- ### 但具體原因不知,需要質性調查
3-4.Cat-Plot¶
In [31]:
sns.set(style="ticks", color_codes=True)
In [32]:
help(sns.catplot)
In [33]:
sns.catplot(x="sex", y="total_bill",
hue="smoker", col="time",
data=tips, kind="bar",
height=4, aspect=.7)
Out[33]:

In [ ]: